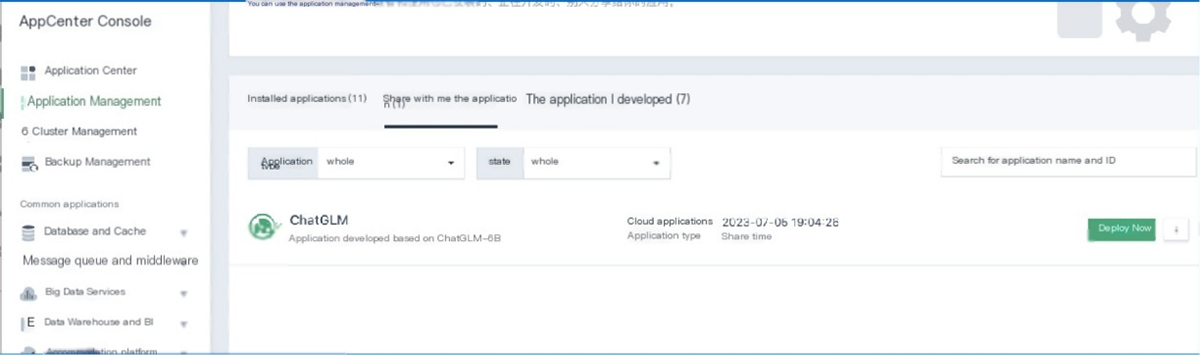
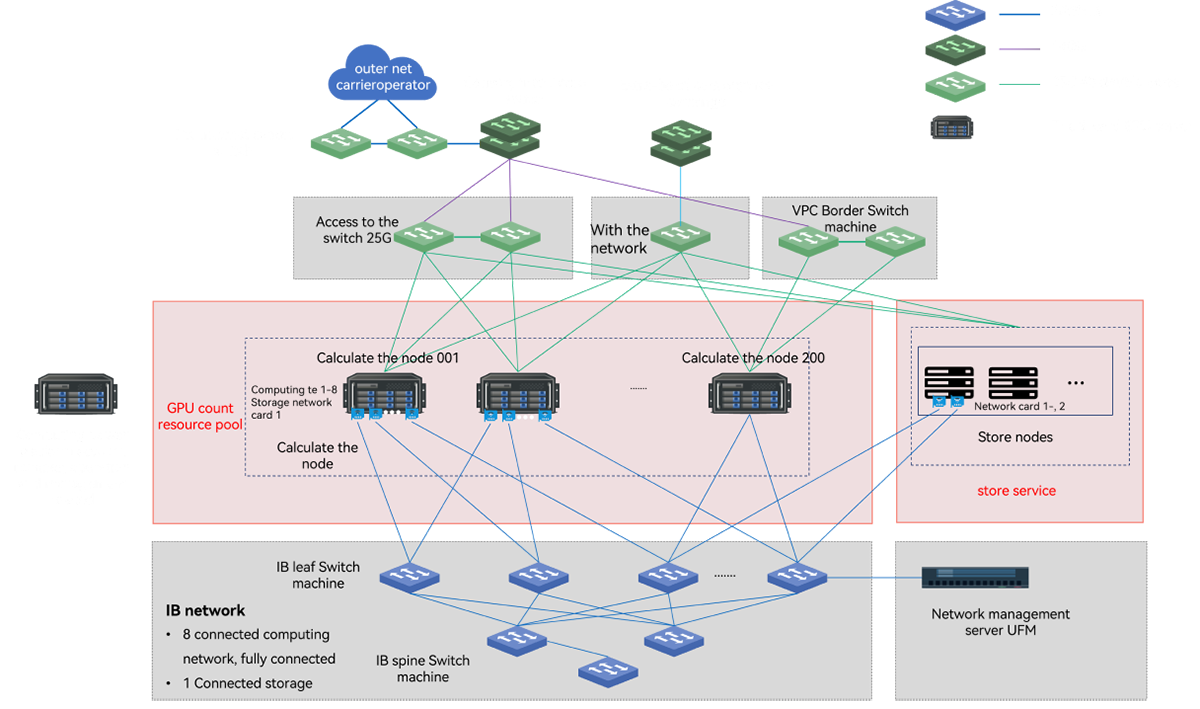
AI Intelligent Computing Platform
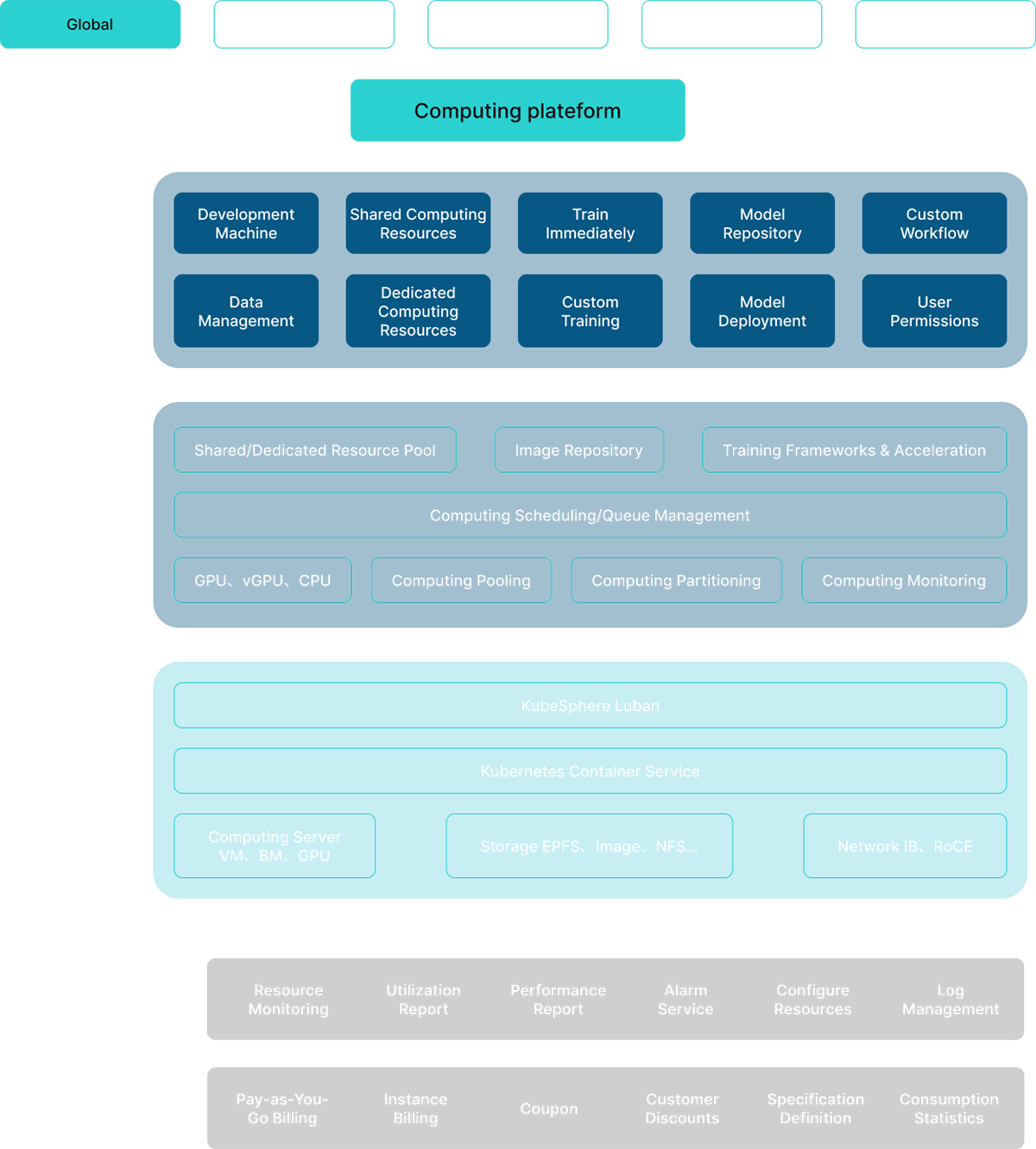
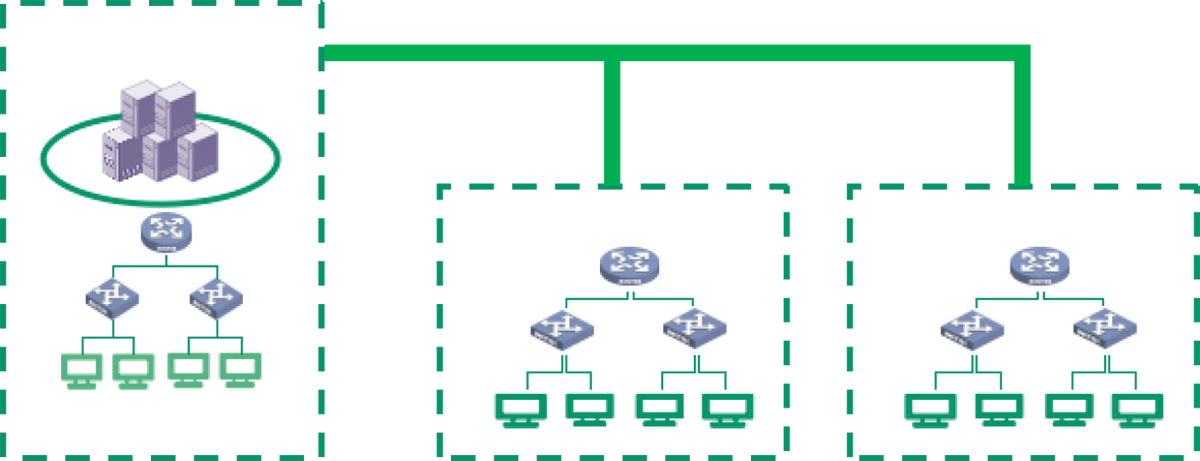
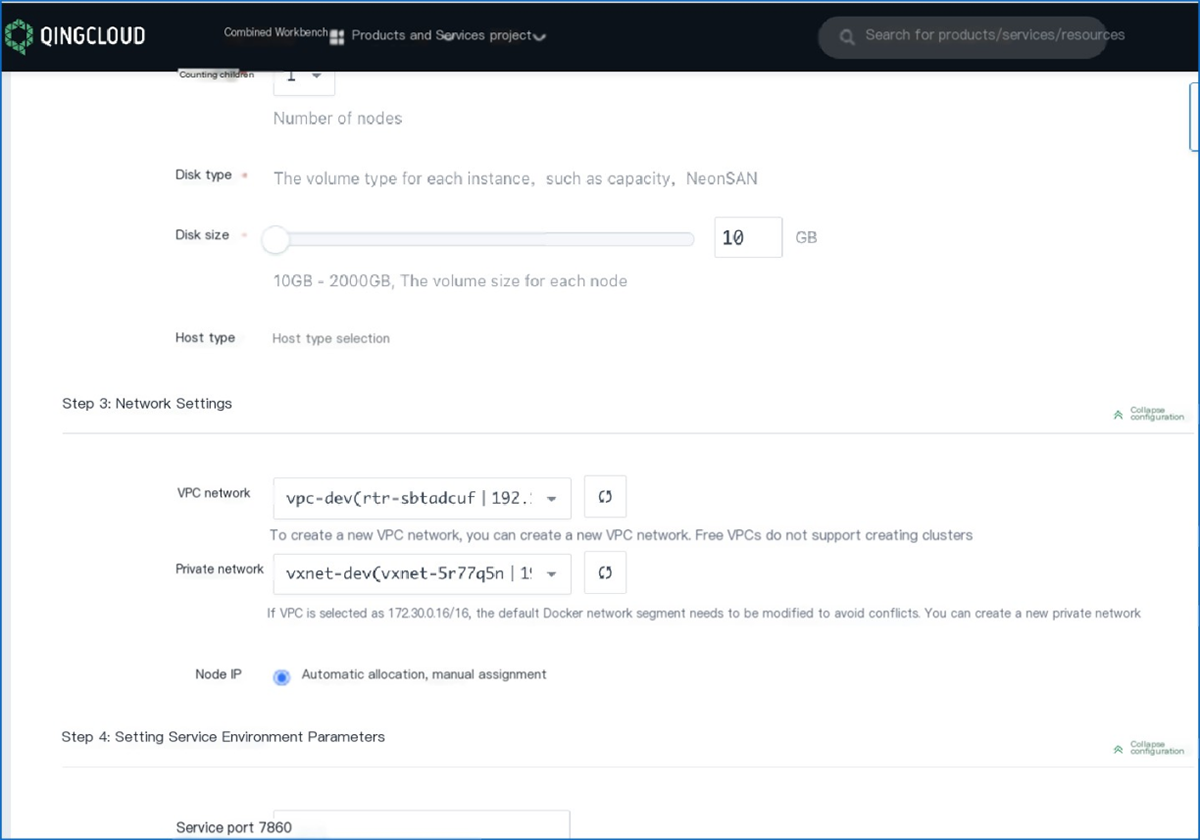
The AI intelligent computing platform is dedicated to creating a new model for the construction and operation of computing power centers. It manages tens of thousands of GPU resources, providing unified scheduling, optimizing strategies for shorter cycles, and enabling on-demand usage. It supports large-scale parallel training scenarios, covering the entire AI computing process from model design, training, deployment, to inference, and manages AI infrastructure like local resources.